| Главная » Статьи » Программирование » Прочие |
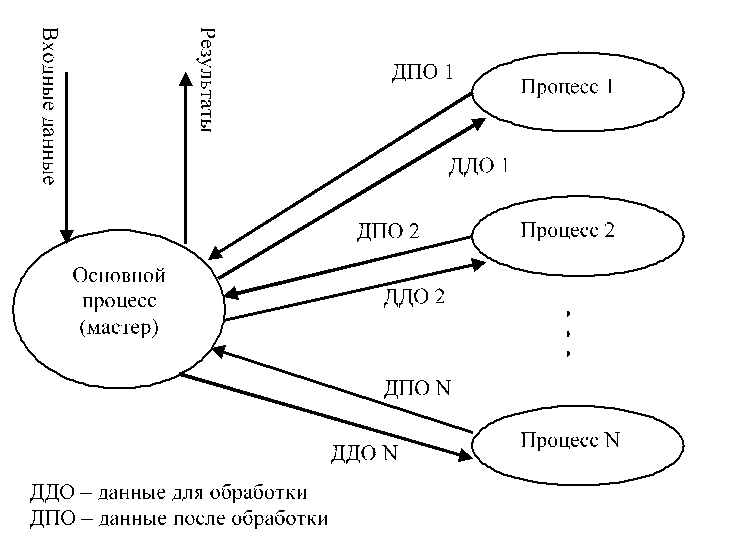
Как правило, программирование для сетевых кластеров отличается от привычной модели программирования для многозадачных систем, построенных на базе одного или множества процессоров. Часто в таких системах необходимо обеспечить только синхронизацию процессов, и нет нужды задумываться об особых способах обмена информацией между ними, т.к. данные обычно располагаются в общей разделяемой памяти. В сети реализация такого механизма затруднительна из-за высоких накладных расходов, связанных с необходимостью предоставлять каждому процессу копию одной и той же разделяемой памяти для работы. Поэтому, обычно, при программировании для сетевых кластеров используется SPMD-технология (Single Program – Multiple Data, одна программа – множественные данные). Идея SPMD в том, чтобы поделить большой массив информации между одинаковыми процессами, которые будут вести обработку своей части данных (рис. 1).
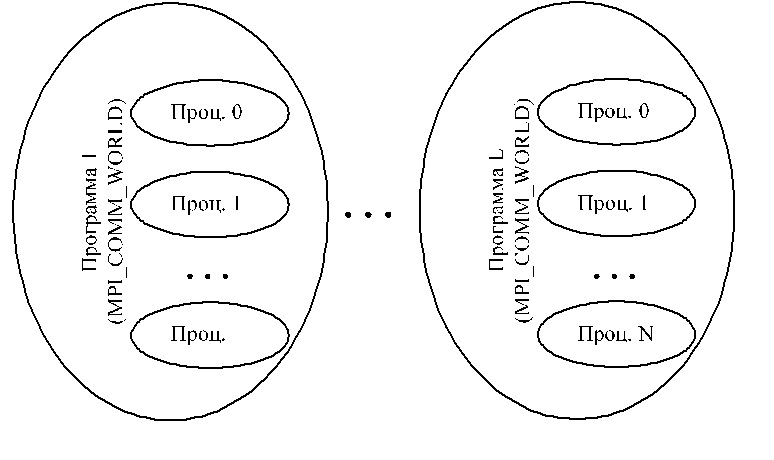
Рис. 1. Схема взаимодействия частей SPMD-программы В случае SPMD-подхода достаточно рассылать время от времени процессам блоки данных, которые требуют трудоемкой обработки, а затем собирать результаты их работы. Если время обработки блока данных одной машиной значительно больше, чем время пересылки этого блока по сети, то сетевая кластерная система становится очень эффективной. Именно такой подход используется в MPI. Здесь всегда есть основной процесс, который производит распределение данных по другим машинам, а после окончания вычислений собирает результаты и показывает их пользователю. Обычно процесс-мастер после распределения данных также выполняет обработку их части, чтобы использовать ресурсы системы наиболее эффективно. Как уже было сказано выше, MPI является стандартом обмена сообщениями. Он обеспечивает низкоуровневые коммуникации и синхронизацию процессов в сетевом кластере. По сути дела, каждое сообщение представляет собой пакет типизированных данных, который один процесс может отправить другому процессу или группе процессов. Все сообщения обладают идентификатором (не обязательно уникальным), который задается программистом и служит для идентификации типа сообщения на принимающей стороне. MPI поставляется в виде библиотеки, подключаемой к среде программирования. Самыми распространенными являются библиотеки для языков Си и Fortran. Также частью MPI является резидент, который запускается на каждой машине кластера и, отвечая на запросы процессов, позволяет им взаимодействовать в сети, а также осуществляет начальный запуск всех процессов, участвующих в расчете и составляющих SPMD-программу, на указанных в файле конфигурации задачи машинах кластера. Каждый MPI-процесс в пределах SPMD-программы уникально идентифицируется своим номером. Допускается объединять процессы в группы, которые могут быть вложенными. Внутри каждой группы все процессы перенумерованы, начиная с нуля. С каждой группой ассоциирован свой коммуникатор (уникальный идентификатор). Поэтому при осуществлении пересылки данных необходимо указать наряду с номером процесса и идентификатор группы, внутри которой производится эта пересылка. Все процессы изначально содержатся в группе с предопределенным идентификатором MPI_COMM_WORLD, который заводится для каждой запускаемой SPMD-программы (рис. 2). Разные SPMD-программы не знаю о существовании друг друга и обмен данными между ними невозможен.
Рис 2. Нумерация процессов и коммуникаторы в MPI Рассмотрим основные функции библиотеки. Все они возвращают целое значение, которое либо равно константе MPI_SUCCESS, либо содержит код произошедшей ошибки. Перед тем, как программа сможет работать с функциями библиотеки необходимо инициализировать MPI с помощью функции: int MPI_Init(int *argc, char ***argv) В качестве аргументов этой функции передаются параметры командной строки, поступающие в функцию main(). Если процессу MPI необходимо узнать свой порядковый номер в группе, то используется функция: int MPI_Comm_rank (MPI_Comm, int *rank) Ее второй параметр будет выходным, содержащим номер процесса в указанной в первом параметре группе. Чтобы узнать размер группы (количество процессов в ней) необходимо применить функцию: int MPI_Comm_size (MPI_Comm, int *ranksize) Для окончания работы с MPI необходимо использовать функцию: int MPI_Finalize() Перед тем, как начать рассмотрение функций передачи/приема сообщений, отметим, какие основные типы данных поддерживает MPI (таблица 1). Таблица 1. Соответствие типов в MPI и языке Cи
Для передачи сообщений в MPI используется ряд функций, которые работают синхронно и асинхронно. В первом случае функция не возвращает управления, пока не завершит свою работу, во втором – сразу возвращает управление, инициировав соответствующую операцию, затем с помощью специальных вызовов есть возможность проконтролировать ход выполнения асинхронной посылки или приема данных. Рассмотрим эти функции подробнее. int MPI_Send(void* buf, int count, Функция выполняет синхронную (с блокировкой) посылку сообщения с идентификатором msgtag (идентификатор выбирается самостоятельно программистом!), состоящего из count элементов типа datatype, процессу с номером dest и коммуникатором comm. Все элементы сообщения расположены подряд в буфере buf. Тип передаваемых элементов datatype должен указываться с помощью предопределенных констант типа (таблица 1). Разрешается передавать сообщение самому себе. Блокировка гарантирует корректность повторного использования всех параметров после возврата из подпрограммы. Следует специально отметить, что возврат из подпрограммы MPI_Send не означает ни того, что сообщение уже передано процессу dest, ни того, что сообщение покинуло процессорный элемент, на котором выполняется процесс, выполнивший MPI_Send. В MPI имеется ряд специальных функций посылки сообщения, устраняющих подобную неопределенность, которые подробно описаны в литературе. int MPI_Recv(void* buf, int count, Прием сообщения с идентификатором msgtag от процесса source с блокировкой. Число элементов в принимаемом сообщении не должно превосходить значения count. Если число принятых элементов меньше значения count, то гарантируется, что в буфере buf изменятся только элементы, соответствующие элементам принятого сообщения. Блокировка гарантирует, что после возврата из подпрограммы все элементы сообщения приняты и расположены в буфере buf. В качестве номера процесса-отправителя можно указать предопределенную константу MPI_ANY_SOURCE - признак того, что подходит сообщение от любого процесса. В качестве идентификатора принимаемого сообщения можно указать константу MPI_ANY_TAG - признак того, что подходит сообщение с любым идентификатором. Если процесс посылает два сообщения другому процессу, и оба эти сообщения соответствуют одному и тому же вызову MPI_Recv, то первым будет принято то сообщение, которое было отправлено раньше. Параметр status содержит служебную информацию о ходе приема, которая может быть использована в программе. status является структурой и содержит поля: MPI_SOURCE, MPI_TAG и MPI_ERROR (источник сообщения, идентификатор сообщения и возникшая ошибка, соответственно). int MPI_Isend(void *buf, int count, Передача сообщения, аналогичная MPI_Send, однако, возврат из подпрограммы происходит сразу после инициализации процесса передачи без ожидания обработки всего сообщения, находящегося в буфере buf. Это означает, что нельзя повторно использовать данный буфер для других целей без получения дополнительной информации о завершении данной посылки. Окончание процесса передачи (т.е. тот момент, когда можно вновь использовать буфер buf без опасения испортить передаваемое сообщение) можно определить с помощью параметра request (идентификатор асинхронной операции определенного в MPI типа MPI_Request) и процедур MPI_Wait и MPI_Test, которые будут рассмотрены ниже. Сообщение, отправленное любой из процедур MPI_Send и MPI_Isend, может быть принято как функцией MPI_Recv, так и MPI_Irecv. int MPI_Irecv(void *buf, int count, Прием сообщения, аналогичный MPI_Recv, однако возврат из подпрограммы происходит сразу после инициализации процесса приема без ожидания получения сообщения в буфере buf. Окончание процесса приема можно определить с помощью параметра request и процедур MPI_Wait и MPI_Test. int MPI_Wait(MPI_Request *request, MPI_Status *status) С помощью этой функции производится ожидание завершения асинхронных процедур MPI_Isend или MPI_Irecv, ассоциированных с идентификатором request. В случае приема, параметры сообщения оказываются в status. int MPI_Test(MPI_Request *request, int *flag, Проверка завершенности асинхронных процедур MPI_Isend или MPI_Irecv, ассоциированных с идентификатором request. В параметре flag возвращает значение 1, если соответствующая операция завершена, и значение 0 в противном случае. Если завершена процедура приема, параметры сообщения оказываются в status. MPI_Test не блокирует программу до окончания соответствующих операций приема/передачи, чем и отличается от MPI_Wait. MPI позволяет работать с некоторыми операциями коллективного взаимодействия. В операциях коллективного взаимодействия процессов участвуют все процессы коммуникатора. Соответствующая процедура должна быть вызвана каждым процессом, быть может, со своим набором параметров. Возврат из процедуры коллективного взаимодействия может произойти в тот момент, когда участие процесса в данной операции уже закончено. Как и для блокирующих процедур, возврат означает то, что разрешен свободный доступ к буферу приема или посылки, но не означает ни того, что операция завершена другими процессами, ни даже того, что она ими начата (если это возможно по смыслу операции). int MPI_Bcast(void *buf, int count, Рассылка сообщения от процесса source всем процессам, включая рассылающий процесс. При возврате из процедуры содержимое буфера buf процесса source будет скопировано в локальный буфер процесса. Значения параметров count, datatype и source должны быть одинаковыми у всех процессов. int MPI_Gather(void *sbuf, int scount, Сборка данных со всех процессов в буфере rbuf процесса dest. Каждый процесс, включая dest, посылает содержимое своего буфера sbuf процессу dest. Собирающий процесс сохраняет данные в буфере rbuf, располагая их в порядке возрастания номеров процессов. Параметр rbuf имеет значение только на собирающем процессе и на остальных игнорируется, значения параметров rcount, datatype и dest должны быть одинаковыми у всех процессов. int MPI_Scatter(void *sbuf, int scount, Обратная к MPI_Gather функция. Процесс source рассылает порции данных из массива sbuf всем процессам группы, на которую указывает коммуникатор comm. Можно считать, что массив sbuf делится на n равных частей, состоящих из scount элементов типа stype, после чего i-я часть посылается i-му процессу. На процессе source существенным являются значений всех параметров, а на остальных процессах – только значения параметров rbuf, rcount, rtype, source и comm. Значения параметров source и comm должны быть одинаковыми у всех процессов. Синхронизация MPI-процессов может быть выполнена с использованием блокирующих процедур приема/посылки сообщений или посредством функции, реализующей барьерную синхронизацию: int MPI_Barrier(MPI_Comm comm) MPI_Barrier блокирует работу процессов, вызвавших данную процедуру, до тех пор, пока все оставшиеся процессы группы comm также не выполнят эту процедуру. MPI продолжает активно развиваться и совершенствовать механизмы работы в сетевом кластере. Так, начиная с версии 2.0 [3], в MPI появилась возможность запускать новые процессы из уже исполняющихся MPI-программ. Это необходимо для реализации модели обработки информации MPMD (Multiple Program – Multiple Data ). Для этого используется процедура: int MPI_Comm_spawn(char *command, char *argv[], Эта подпрограмма запускает maxprocs процессов, обозначенных командой command с аргументами, находящимися в массиве строк argv. В зависимости от реализации стандарта система может запустить меньшее количество процессов или выдать ошибки при невозможности запустить maxprocs процессов. Нами рассмотрены самые основные функции MPI, составляющие менее половины всех имеющихся. Для более подробного изучения данной библиотеки можно использовать документацию по данному стандарту [1-5]. Для программирования с использованием MPI в среде Visual C++ в Windows мы будем использовать свободно распространяемую библиотеку WinMPI версии 1.3, которая в полной мере реализует стандарт MPI 1.1. Для данной версии справедливо все сказанное выше за исключением возможности динамического запуска процессов MPI. Необходимо установить WinMPI в любую директорию (по умолчанию это C:\WMPI1.3) | |||||||||||||||||||||||||||
| Просмотров: 1733 | | | |||||||||||||||||||||||||||
| Всего комментариев: 0 | |