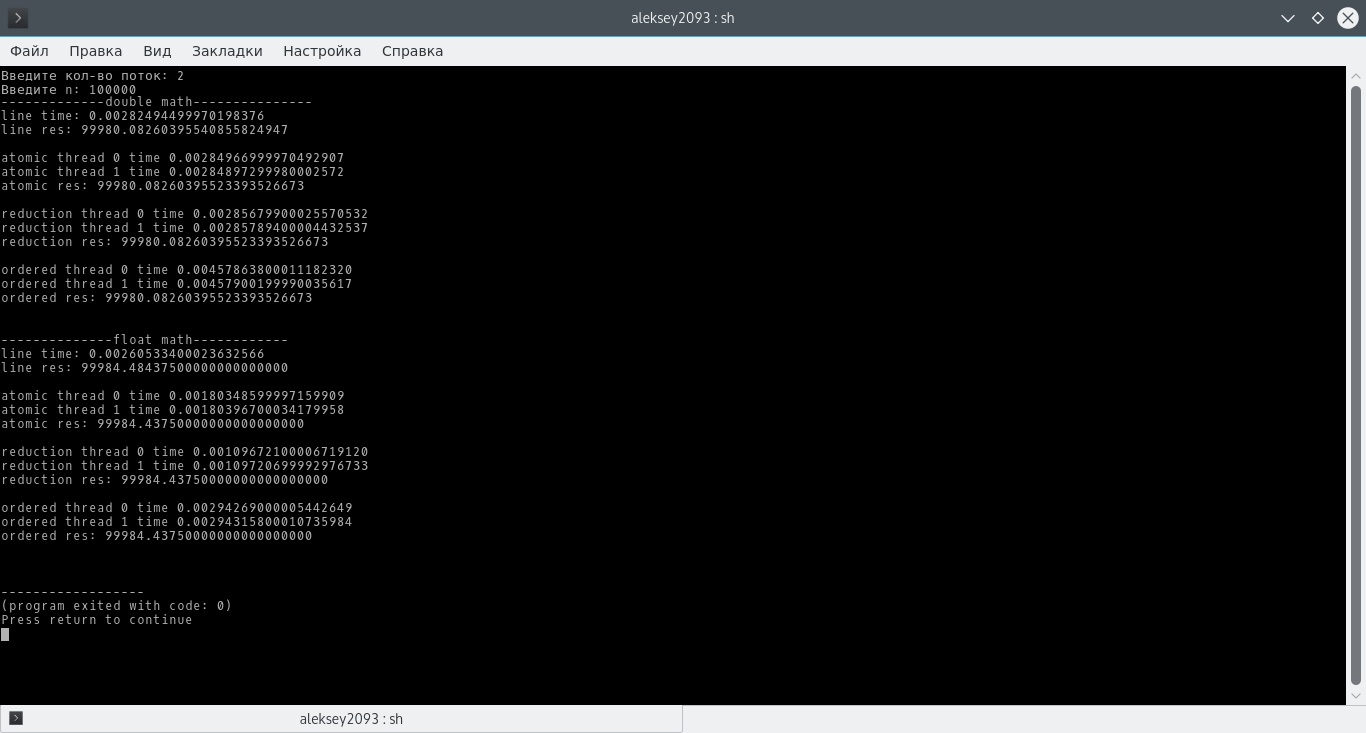
| Алексей | Дата: Четверг, 31.03.2016, 20:23 | Сообщение # 2 |
 Продвигающийся
Группа: Администраторы
Сообщений: 324
Статус: Оффлайн
| При подсчете числового ряда не совпадают полученные суммы паралллеьных циклов с суммой полученной в последовательном цикле.
Код #include <cstdio>
#include <stdio.h>
#include <stdlib.h>
#include <iostream> //std
#include <sstream>
#include <fstream>
#include <time.h>
#include <omp.h>
using namespace std;
int n = -1;
int th = -1;
void atom_2()
{
float sum_omp = 0;
#pragma omp parallel num_threads(th)
{
double tim = omp_get_wtime();
#pragma omp for reduction(+:sum_omp)
for (int i=0;i<n;i++)
{
float x = i;
#pragma omp atomic
sum_omp += (x*x*x+1)/((x+1)*(x+1)*(x+1))+(x/(x*x+1));
}
tim = omp_get_wtime() - tim;
printf("\natomic thread %d time %.20f", omp_get_thread_num(), tim);
}
printf ("\natomic res: %.20f", sum_omp);
}
void shed_2()
{
float sum_omp = 0;
#pragma omp parallel num_threads(th)
{
double tim = omp_get_wtime();
#pragma omp for reduction(+:sum_omp)
for (int i=0;i<n;i++)
{
float x = i;
sum_omp += (x*x*x+1)/((x+1)*(x+1)*(x+1))+(x/(x*x+1));
}
tim = omp_get_wtime() - tim;
printf("\nreduction thread %d time %.20f", omp_get_thread_num(), tim);
}
printf ("\nreduction res: %.20f", sum_omp);
}
void ord_2()
{
float sum_omp = 0;
#pragma omp parallel num_threads(th)
{
double tim = omp_get_wtime();
#pragma omp for ordered reduction(+:sum_omp)
for (int i=0;i<n;i++)
{
float x= i;
#pragma omp ordered
sum_omp += (x*x*x+1)/((x+1)*(x+1)*(x+1))+(x/(x*x+1));
}
tim = omp_get_wtime() - tim;
printf("\nordered thread %d time %.20f", omp_get_thread_num(), tim);
}
printf ("\nordered res: %.20f", sum_omp);
}
void main_2()
{
float sum = 0;
double t = omp_get_wtime();
for (double x=0;x<n;x++)
{
sum+=(x*x*x+1)/((x+1)*(x+1)*(x+1))+(x/(x*x+1));
}
t = omp_get_wtime() -t;
cout << "\n\n--------------float math------------";
printf("\nline time: %.20f", t);
printf("\nline res: %.20f", sum); cout << "\n";
atom_2(); cout << "\n";
shed_2(); cout << "\n";
ord_2(); cout << "\n";
}
void atom()
{
double sum_omp = 0;
#pragma omp parallel num_threads(th)
{
double tim = omp_get_wtime();
#pragma omp for reduction(+:sum_omp)
for (int i=0;i<n;i++)
{
double x = i;
#pragma omp atomic
sum_omp += (x*x*x+1)/((x+1)*(x+1)*(x+1))+(x/(x*x+1));
}
tim = omp_get_wtime() - tim;
printf("\natomic thread %d time %.20f", omp_get_thread_num(), tim);
}
printf ("\natomic res: %.20f", sum_omp);
}
void shed()
{
double sum_omp = 0;
#pragma omp parallel num_threads(th)
{
double tim = omp_get_wtime();
#pragma omp for reduction(+:sum_omp)
for (int i=0;i<n;i++)
{
double x = i;
sum_omp += (x*x*x+1)/((x+1)*(x+1)*(x+1))+(x/(x*x+1));
}
tim = omp_get_wtime() - tim;
printf("\nreduction thread %d time %.20f", omp_get_thread_num(), tim);
}
printf ("\nreduction res: %.20f", sum_omp);
}
void ord()
{
double sum_omp = 0;
#pragma omp parallel num_threads(th)
{
double tim = omp_get_wtime();
#pragma omp for ordered reduction(+:sum_omp)
for (int i=0;i<n;i++)
{
double x= i;
#pragma omp ordered
sum_omp += (x*x*x+1)/((x+1)*(x+1)*(x+1))+(x/(x*x+1));
}
tim = omp_get_wtime() - tim;
printf("\nordered thread %d time %.20f", omp_get_thread_num(), tim);
}
printf ("\nordered res: %.20f", sum_omp);
}
int main()
{
double sum = 0;
while (th <= 0)
{
cout << "Введите кол-во поток: "; cin >> th;
}
while (n <= 0)
{
cout << "Введите n: "; cin >> n;
}
double t = omp_get_wtime();
for (double x=0;x<n;x++)
{
sum+=(x*x*x+1)/((x+1)*(x+1)*(x+1))+(x/(x*x+1));
}
t = omp_get_wtime() -t;
cout << "-------------double math---------------";
printf("\nline time: %.20f", t);
printf("\nline res: %.20f", sum); cout << "\n";
atom(); cout << "\n";
shed(); cout << "\n";
ord(); cout << "\n";
main_2();
cout << endl;
return 0;
}
Снимок:
|
| |
|
|
| Алексей | Дата: Пятница, 01.04.2016, 21:18 | Сообщение # 3 |
|
Продвигающийся
Группа: Администраторы
Сообщений: 324
Статус: Оффлайн
| Цитата Алексей (  ) При подсчете числового ряда не совпадают полученные суммы параллельных циклов с суммой полученной в последовательном цикле. |
| |
|
|
| Алексей | Дата: Суббота, 28.05.2016, 05:58 | Сообщение # 4 |
|
Продвигающийся
Группа: Администраторы
Сообщений: 324
Статус: Оффлайн
| MPI. Приведение матрицы к треугольному виду. Добавлены параллельные циклы за счет openMP. Следующий г
Код #include <mpi.h>
#include <stdio.h>
#include <omp.h>
#include <string.h>
#include <math.h>
#define SIZEMASS 10
int main (int argc, char **argv)
{
char message[20];
int myrank;
int size;
int i,j,z,k,r,c;
int col1,col2; //col1 начальный столбец col2 = конечный столбец
double matrix[SIZEMASS*SIZEMASS]; //везде инициализируем матрицу
double maxValue;
double tmp;
double zamenitel;
double starttime, endtime;
int maxN;
MPI_Status status;
MPI_Init (&argc, &argv);
MPI_Comm_rank (MPI_COMM_WORLD, &myrank);
MPI_Comm_size(MPI_COMM_WORLD, &size);
printf("my rank %d. \n sizeworld %d. \n",myrank,size);
if (myrank==0) /* это просто приветствие */
{
strcpy (message, "Hello, there");
for (i = 1;i<size;i++)
MPI_Send(message, strlen(message), MPI_CHAR, i, 99, MPI_COMM_WORLD);
}
else
{
MPI_Recv (message, 20, MPI_CHAR, 0, 99, MPI_COMM_WORLD, &status);
printf ("received: %s:\n", message);
}
//это if else пересылает массив от основного узла на остальные
if (myrank == 0)
{
//заполняем массив
#pragma omp parallel for
for (i=0;i<SIZEMASS;i++)
for(j=0;j<SIZEMASS;j++)
matrix[i*SIZEMASS+j] = i+1+j+1;
//пересылаем массив всем участникам процесса кроме себя
for (i = 1;i<size;i++) //вопрос интересный, а можно ли этот цикл засунуть в omp, возможно ли использовать параллельно несколько MPI_Send
{
for (j = 0; j <SIZEMASS*SIZEMASS;j++)
{
MPI_Send(&matrix[j], 1, MPI_DOUBLE, i, 20, MPI_COMM_WORLD);
}
}
}
else
{
for (i = 0;i<SIZEMASS*SIZEMASS;i++)
{
MPI_Recv(&matrix[i], 1, MPI_DOUBLE, i, 20, MPI_COMM_WORLD, &status);
}
}
MPI_Barrier(MPI_COMM_WORLD);
//теперь мы должны сказать узлам какие столбцы они возьмут
if (myrank == 0)
{
col1 = 0;
col2 = SIZEMASS / size;
for (i=0;i<size;i++)
{
MPI_Send(&col2, 1, MPI_INT, i, 21, MPI_COMM_WORLD);
}
}
else
{
MPI_Recv(&col2,1, MPI_INT, 0, 21, MPI_COMM_WORLD, &status);
col1 = col2 * myrank;
col2 = col1 + col2 + 1;
}
if (myrank == 0)
starttime = MPI_Wtime();
MPI_Barrier(MPI_COMM_WORLD); //теперь мы имеем size кластеров на каждом из которых есть исходная матрица и каждый знает с каким столбцом он работает
for(i=0;i<SIZEMASS-1;i++) //идем по этому циклу на всех узлах кластера
{
if (i >= col1 && i<= col2) //если это условие выполнено, то мы находимся в том узле, который должен будет производить поиск максимального элемента стобца с которым он работает
//так же условие буду использовать ниже при замене строк под диагональю на нули потому, что это делает только текущий узел, а остальные производят вычисления
{
maxN = i*SIZEMASS+i; //индекс текущего элемента главной диагонали
maxValue = fabs(matrix[maxN]); //абсолютное значение текущего элемента главной диалогнали
#pragma omp parallel for private(tmp)
for(j=i+1;j<SIZEMASS;j++) //ищем максимальный элемент вот этот цикл потом запихиваем в openMP
{
tmp = fabs(matrix[j*SIZEMASS+i]);
if (tmp>maxValue)
{
maxValue = tmp;
maxN = j*SIZEMASS+i;
}
}
if (maxN > i)
{
#pragma omp parallel for
for (j = col1;j<col2;j++) //тут текущий ранк который производил поиск максимального элемента меняет строки местами в пределах своих столбцов
{
tmp = matrix[i*SIZEMASS+j];
matrix[i*SIZEMASS+j] = matrix[maxN*SIZEMASS+j];
matrix[maxN*SIZEMASS+j] = tmp;
}
zamenitel = matrix[i*SIZEMASS+i];
/*отправляем всем узлам информацию о том, что некоторые строчки нужно поменять местами причем быстренько*/
for (j = 0; j < myrank; j++)
{
MPI_Send(&maxN,1, MPI_INT, j, 23, MPI_COMM_WORLD);
MPI_Send(&zamenitel,1, MPI_DOUBLE, j, 15, MPI_COMM_WORLD);
}
for (j = myrank + 1; j < size; j++)
{
MPI_Send(&maxN,1, MPI_INT, j, 23, MPI_COMM_WORLD);
MPI_Send(&zamenitel,1, MPI_DOUBLE, j, 15, MPI_COMM_WORLD);
}
//отправили всем элемент главной диагонали надо сделать так, чтобы от правлялся сразу после замены
//чтобы отправлялся сразу нужно раздробить цикл выше
}
else
{
/* есть нулевой элемент из-за которого мы в пролете потому, что элемент диагонали 0, поэтому отправляем всем "-1" дабы должить, чтобы вышли вон из цикла и ничего более не делали в проге */
maxN = -1;
for (r = 0; r < myrank; r++)
MPI_Send(&maxN,1, MPI_INT, r, 23, MPI_COMM_WORLD);
for (r = myrank + 1; r < size; r++)
MPI_Send(&maxN,1, MPI_INT, r, 23, MPI_COMM_WORLD);
break;
}
}
else //тут другие узлы, принимает номер строки с которой меняем основную и производят замену в пределах своих столбцов
{
MPI_Recv(&maxN,1, MPI_INT, MPI_ANY_SOURCE, 23, MPI_COMM_WORLD, &status);
if (maxN == -1)
break;
MPI_Recv(&zamenitel,1, MPI_DOUBLE, MPI_ANY_SOURCE, 15, MPI_COMM_WORLD, &status); //ура мы получили заменитель, наверное
#pragma omp parallel for private(tmp)
for (j = col1;j<col2;j++) //тут текущий ранк который производил поиск максимального элемента меняет строки местами в пределах своих столбцов
{
tmp = matrix[i*SIZEMASS+j];
matrix[i*SIZEMASS+j] = matrix[maxN*SIZEMASS+j];
matrix[maxN*SIZEMASS+j] = tmp;
}
}
//отлтчно все поменяли
//теперь нужно создать на всех узлах переменную элемента главной диагонали текущего узла по сути лучше это сделать в предыдущем if else который выше
//этого сообщения, что я собственно сейчас и сделаю
MPI_Barrier(MPI_COMM_WORLD);
if (i >= col1 && i<= col2)
{
for (j = i + 1; j < SIZEMASS; j++) //это цикл по строкам
{
tmp = matrix[j*SIZEMASS+i] / zamenitel; //а вот это кажется придется всем отправлять для того чтобы умножали на нужное
#pragma omp parallel
{
#pragma omp sections nowait
{
#pragma omp section
for (r = myrank + 1; r < size; r++)
MPI_Send(&tmp,1, MPI_DOUBLE, r, 24, MPI_COMM_WORLD);
#pragma omp section
matrix[j*SIZEMASS+i] = 0;
}
#pragma omp for
for (c = i + 1; c < col2; c++)
matrix[j*SIZEMASS+c] = matrix[j*SIZEMASS+c] - matrix[j*SIZEMASS+c] * tmp; /*а по факту комментарий выше отменяется потому отправлять придется вот это.
Хотя, стоп погоди я же тут умножаю элемент строки на которой мы в верхнем цикле на элемент строки из этого цикла тогда я нахожусь в нужном диапозоне*/
}
}
}
else if (i < col1)
{
for(j = i + 1; j < SIZEMASS; j++)
{
MPI_Recv(&tmp,1, MPI_DOUBLE, MPI_ANY_SOURCE, 24, MPI_COMM_WORLD, &status);
#pragma omp parallel for
for (c = col1; c < col2; c++)
matrix[i*SIZEMASS+c] = matrix[j*SIZEMASS+c] - matrix[j*SIZEMASS+c] * tmp;
}
}
}
if (myrank == 0)
{
endtime = MPI_Wtime();
for (i=0;i<size;i++) //узлы
{
for (k=0;k<col2;k++)
{
MPI_Recv(&z,1,MPI_INT,MPI_ANY_SOURCE,81, MPI_COMM_WORLD, &status); //столбец
for (j=0;j<SIZEMASS;j++) //строки
{
MPI_Recv(&tmp,1,MPI_DOUBLE,MPI_ANY_SOURCE,82,MPI_COMM_WORLD, &status);
matrix[j*SIZEMASS+z] = tmp;
}
}
}
printf("time work: %f \n",endtime-starttime);
}
else
{
for (i=col1;i<col2;i++)
{
MPI_Send(&i,1,MPI_INT,0,81,MPI_COMM_WORLD);
for (j=0;j<SIZEMASS;j++)
MPI_Send(&matrix[j*SIZEMASS+i],1,MPI_DOUBLE,0,82,MPI_COMM_WORLD);
}
}
MPI_Barrier(MPI_COMM_WORLD);
MPI_Finalize();
} |
| |
|
|